Задание. Асинхронный скрэппер для bash.im
Скачаем коллекцию комиксов с bash.im за целый год. Конечно же, асинхронно.
Введение в задачу
Итак, мы уже научились делать скрэпперы для сайтов с помощью библиотеки BeautifulSoup 4. Теперь задача гораздо серьёзнее. Все мы знаем сборник цитат Рунета bash.im (бывший bash.org.ru). С августа 2007 года там работает раздел «Комиксы», в котором публикуются выбранные администрацией ресурса рисунки читателей по мотивам цитат.
Напишем скрипт, который будет скачивать все комиксы за указанный год.
Для того, чтобы найти ссылки на изображения, нам понадобится BeautifulSoup. Страница со ссылками на комиксы за весь год находится по такому адресу:
https://bash.im/comics-calendar/YYYY
Где YYYY — это четырёхзначный номер года. Напомню, что до августа 2007 года раздела «Комиксы» не было.
Например, вот список комиксов за 2007 год.
Там мы видим список ссылок на страницы отдельных комиксов. Извлечь их нетрудно, это просто ссылки, сосредоточенные в блоке
<div id="calendar">.....</div>
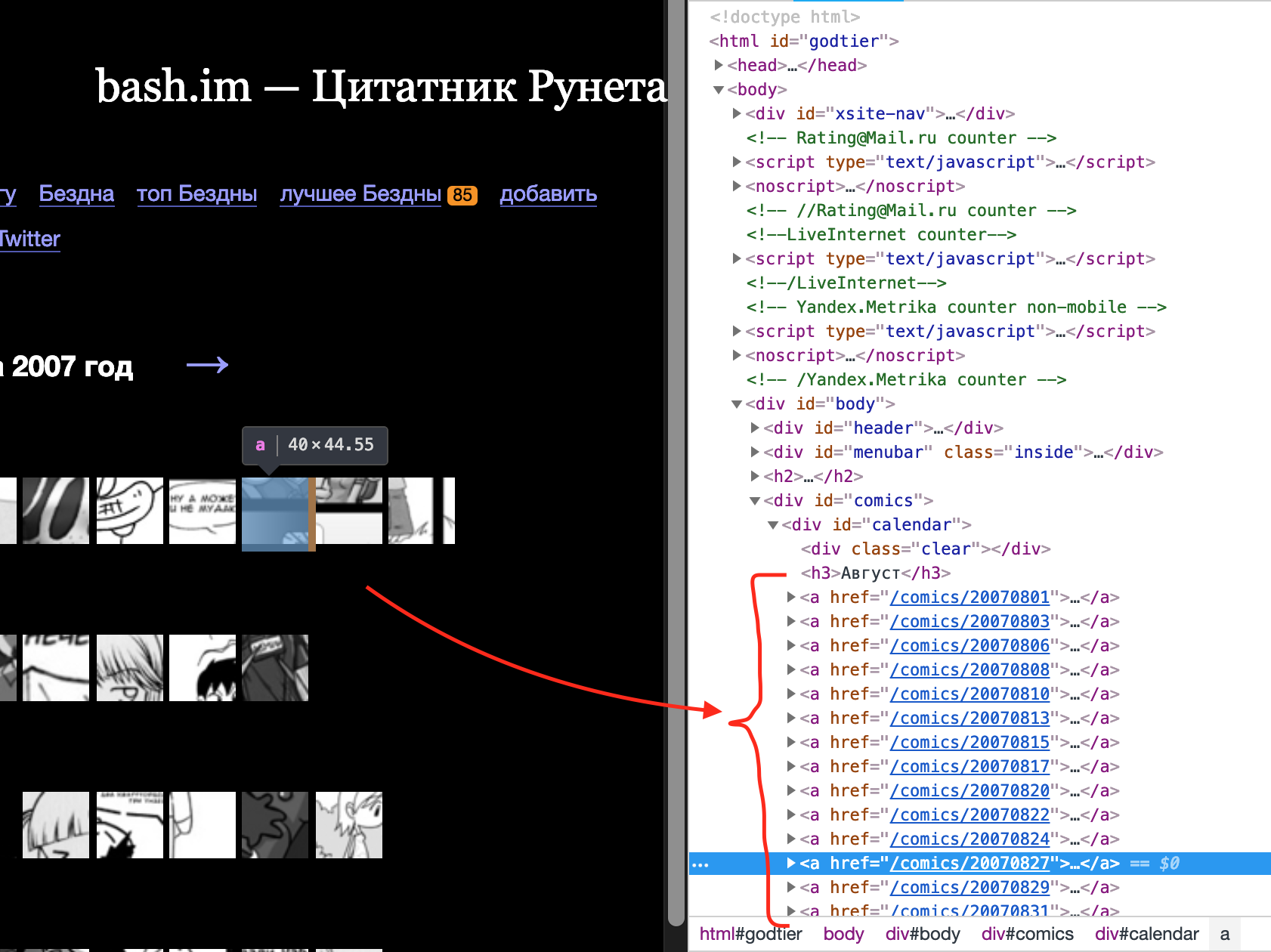
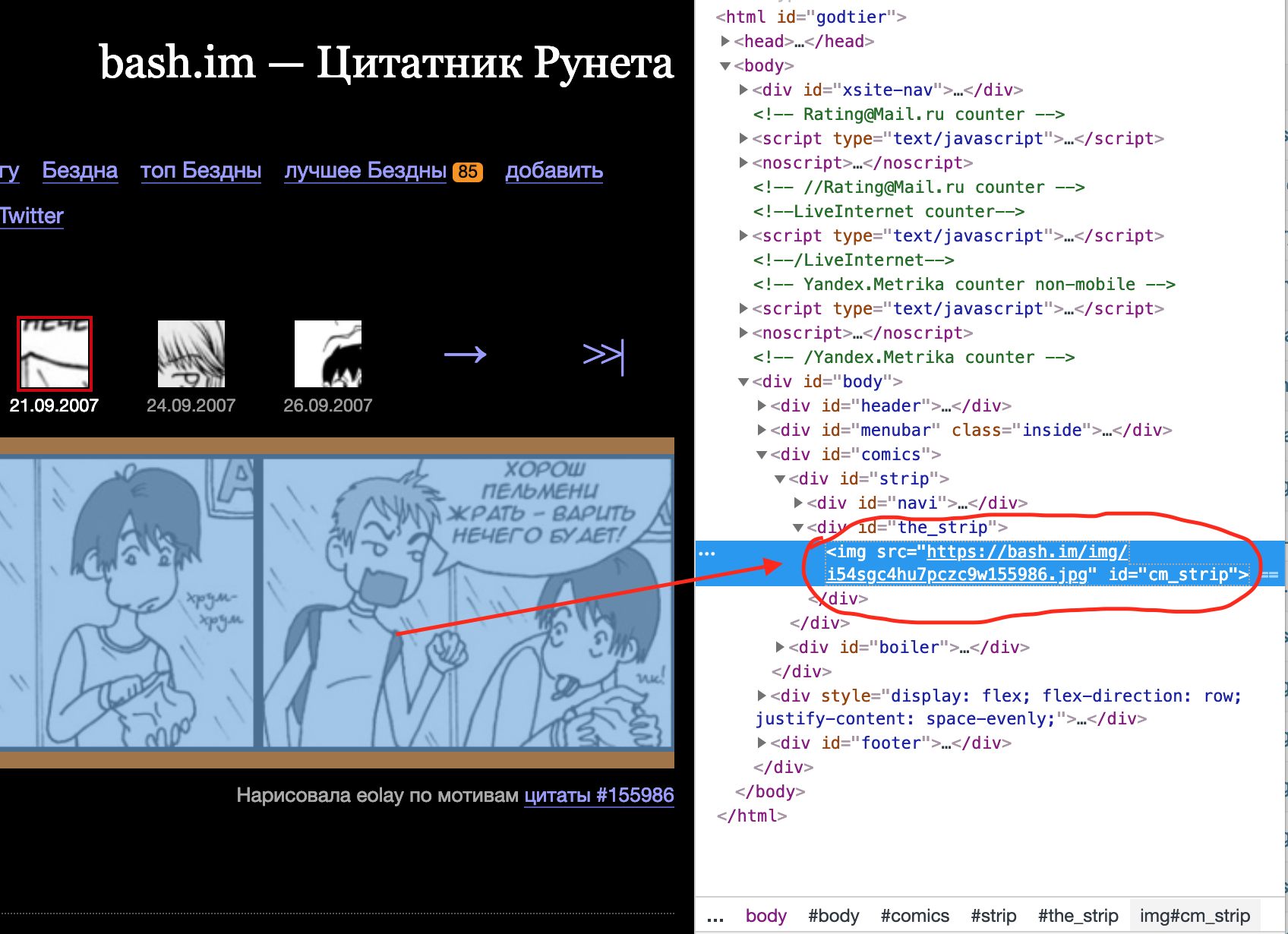
Каждая из этих ссылок ведёт на страницу комикса. На этой странице находится интересующий нас тег
<img src="https://bash.im/img/i54sgc4hu7pczc9w155986.jpg" id="cm_strip">
В атрибуте src которого и содержится ссылка на файл изображения.
Реализация
Скрипт должен делать следующее:
- Запросить у пользователя интересующий его год (как вариант — воспользоваться аргументами командной строки)
- Получить страницу календаря за указанный год 💥
- На этой странице найти ссылки на все страницы комиксов за этот год
- Получить все страницы комиксов по этим ссылкам 💥
- На каждой странице найти и скачать файл изображения с комиксом 💥
При возникновении ошибок на этапе 2 нужно сообщить об ошибке и прекратить работу, а если что-то пойдёт не так на этапах 4 или 5, следует просто пропустить такую страницу и перейти к следующему комиксу.
💥 — помеченные этим значком этапы нужно реализовать асинхронно. Соответственно, вместо привычной нам библиотеки requests следует использовать aiohttp и скачивать страницы и файлы изображений параллельно. Записывать файлы на диск можно так же параллельно, с помощью библиотеки aiofiles.
Замечания по реализации
При сохранении файлов изображений нужно давать им имена вот такого формата:
bash.im_YYYY-MM-DD_СССССС.jpg
где YYYY-MM-DD — дата публикации комикса в виде «год-месяц-день», а СССССС — номер соответствующей цитаты. И дату публикации, и номер цитаты можно найти на странице комикса.
При получении страниц отдельных комиксов стоит делать небольшую случайную задержку перед запросами, чтобы сайт не решил, что вы пытаетесь устроить атаку типа DoS. Например, вот так:
...
# Функция uniform — как randint, но для чисел с плавающей точкой
from random import uniform
...
...
async def fetch_comics_page(session, url):
await asyncio.sleep(uniform(0.2, 0.7))
resp = await session.get(url)
...
Ошибка SSLCertVerificationError
Вы можете столкнуться с ошибкой такого вот вида при попытке получить ответ от сайта с помощью aiohttp:
SSL handshake failed on verifying the certificate
......
aiohttp.client_exceptions.ClientConnectorCertificateError: Cannot connect to host
bash.im:443 ssl:True [SSLCertVerificationError: (1, '[SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed: self signed certificate in certificate chain (_ssl.c:1056)')]
Ничего страшного, просто сертификат безопасности сайта bash.im не удовлетворяет строгим требованиям aiohttp. Чтобы обойти это ограничение, нужно выключить проверку подлинности сертификата при создании сессии, указав соответствующий параметр коннектора:
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as sess:
...
Отладка
Выполняйте и реализуйте задачу по частям. Пользуйтесь print для отладочного вывода.
Во время отладки ограничивайте количество скачиваемых страниц и комиксов. Например, получайте не все страницы за год, а только первые пять. Это сильно ускорит дело. Не забудьте убрать это ограничение и снова всё проверить, если скрипт будет устойчиво работать на малом числе страниц.
Лично я бы рекомендовал скачивать комиксы 2008-2012 года, тогда над ними работало много разных художников. Последние несколько лет все комиксы рисуют всего лишь два-три автора, там не так интересно.